Publications
SALVE: A 3D Reconstruction Benchmark of Wounds from Consumer-grade Videos
Remi Chierchia, Leo Lebrat, David Ahmedt-Aristizabal, Olivier Salvado, Clinton Fookes, and Rodrigo Santa CruzIEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025.

We present a comprehensive evaluation of 3D wound reconstruction methods from consumer-grade videos, introducing the SALVE dataset of realistic wound phantoms. Using this dataset, we evaluate traditional photogrammetry and modern neural rendering approaches, highlighting key differences in surface quality and suitability for clinical use.
Syn3DWound: A Synthetic Dataset for 3D Wound Bed Analysis
Léo Lebrat, Rodrigo Santa Cruz, Remi Chierchia, Yulia Arzhaeva, Mohammad Ali Armin, Joshua Goldsmith, Jeremy Oorloff, Prithvi Reddy, Chuong Nguyen, Lars Petersson, et al.IEEE International Symposium on Biomedical Imaging (ISBI) 2024
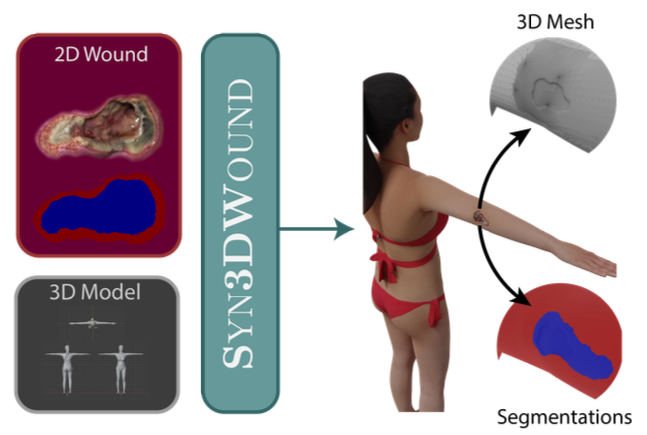
Syn3DWound is a simulated wound dataset with 2D/3D annotations, enabling benchmarking of segmentation and morphometry methods for automated wound analysis.
Divide and Conquer: Rethinking the Training Paradigm of Neural Radiance Fields
Rongkai Ma, Leo Lebrat, Rodrigo Santa Cruz, Gil Avraham, Yan Zuo, Clinton Fookes, and Olivier SalvadoarXiv preprint arXiv:2401.16144 (2024)
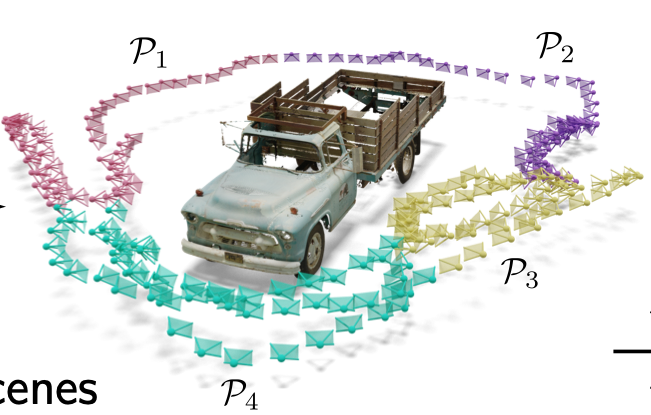
NeRFs typically treat all training images as equally important, leading to poor performance on complex views. We propose a training paradigm that clusters views by visual similarity, trains specialized models per group, and distills their knowledge into a unified model. This approach improves rendering quality without sacrificing efficiency.
Localisation of Racial Information in Chest X-Ray for Deep Learning Diagnosis
Olivier Salvado, Salamata Konate, Rodrigo Santa Cruz, Andrew Bdadley, Judy Wawira Gichoya, Laleh Seyyed-Kalantari, Brandon Price, Clinton Fookes, and Léo LebratIn IEEE International Symposium on Biomedical Imaging (ISBI) 2024
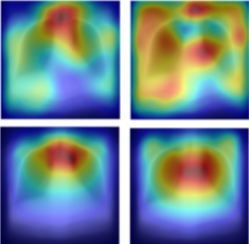
Deep learning models for chest X-ray classification can encode racial information, risking diagnostic bias. We explore where this information resides by comparing atlas-based differences using non-linear registration and saliency maps. Our analysis reveals spatial patterns distinguishing Black and White subjects and examines their alignment with model explanations.
NeRF Director: Revisiting View Selection in Neural Volume Rendering
Wenhui Xiao, Rodrigo Santa Cruz, David Ahmedt-Aristizabal, Olivier Salvado, Clinton Fookes, and Leo LebratIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024
Bias Identification with RankPix Saliency
Salamata Konate, Léo Lebrat, Rodrigo Santa Cruz, Clinton Fookes, Andrew Bradley, and Olivier SalvadoIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2023
Generalization Properties of Geometric 3D Deep Learning Models for Medical Segmentation
Léo Lebrat, Rodrigo Santa Cruz, Reuben Dorent, Javier Urriola Yaksic, Alex Pagnozzi, Gregg Belous, Pierrick Bourgeat, Jurgen Fripp, Clinton Fookes, and Olivier SalvadoIEEE International Symposium on Biomedical Imaging (ISBI) 2023
DBCE: a saliency method for medical deep learning through anatomically-consistent free-form deformations
Joshua Peters, Léo Lebrat, Rodrigo Santa Cruz, Aaron Nicolson, Gregg Belous, Salamata Konate, Parnesh Raniga, Vincent Dore, Pierrick Bourgeat, Jurgen Mejan-Fripp, et al.IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2023
When to Use Augmentation—Variability Insufficient for Cortical Thickness Estimation Improvement
Filip Rusak, Rodrigo Santa Cruz, Hilda Chourak, Elliot Smith, Jurgen Fripp, Clinton Fookes, Pierrick Bourgeat, and Andrew P BradleyIEEE International Symposium on Biomedical Imaging (ISBI) 2023
CSIRO at ImageCLEFmedical Caption 2022
Leo Lebrat, Aaron Nicolson, Rodrigo Santa Cruz, Gregg Belous, Bevan Koopman, and Jason DowlingCLEFmedical Caption 2022
Quantifiable brain atrophy synthesis for benchmarking of cortical thickness estimation methods
Filip Rusak, Rodrigo Santa Cruz, Léo Lebrat, Ondrej Hlinka, Jurgen Fripp, Elliot Smith, Clinton Fookes, Andrew P Bradley, Pierrick Bourgeat, Alzheimer’s Disease Neuroimaging Initiative, et al.Medical Image Analysis 82 (2022), p. 102576
Lesser of two evils improves learning in the context of cortical thickness estimation models-choose wisely
Filip Rusak, Rodrigo Santa Cruz, Elliot Smith, Jurgen Fripp, Clinton Fookes, Pierrick Bourgeat, and Andrew P BradleyIn MICCAI Workshop on Data Augmentation, Labelling, and Imperfections
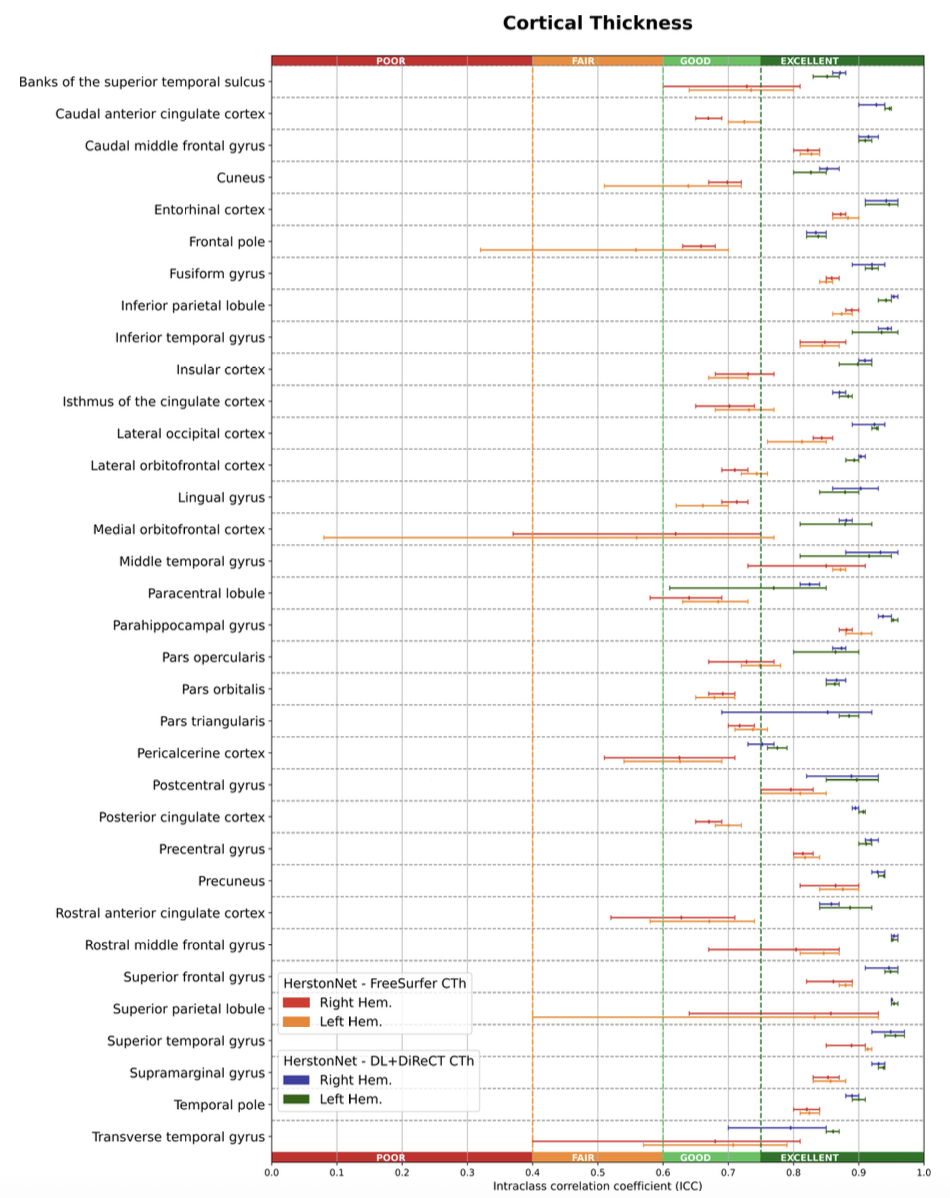
We investigate how the choice of automatic labels affects the performance of HerstonNet, a state-of-the-art ML model for cortical thickness estimation, showing that DL+DiReCT labels lead to notably higher accuracy than those from FreeSurfer.
CorticalFlow++: Boosting Cortical Surface Reconstruction Accuracy, Regularity, and Interoperability
Rodrigo Santa Cruz*, Léo Lebrat*, Darren Fu, Pierrick Bourgeat, Jurgen Fripp, Clinton Fookes, Olivier SalvadoIn International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2022. * equal contribution.
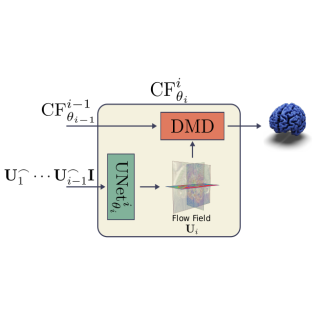
This paper proposes modifications to our corticalflow method that improve its accuracy and interoperability with existing surface analysis tools, while not sacrificing its fast inference time and low GPU memory consumption. Using large-scale datasets, we demonstrate the proposed changes provide more geometric accuracy and surface regularity while keeping the reconstruction time and GPU memory requirements (during inference) almost unchanged.
Cortical Flow: A Diffeomorphic Mesh Deformation Network for Cortical Surface Reconstruction
Léo Lebrat*, Rodrigo Santa Cruz*, Frederic de Gournay, Pierrick Bourgeat, Jurgen Fripp, Darren Fu, Clinton Fookes, Olivier SalvadoIn Conference on Neural Information Processing Systems (NeurIPS), 2021. * equal contribution.

In this paper, we introduce CorticalFlow, a new geometric deep-learning model that, given a 3-dimensional image, learns to deform a reference template towards a targeted object. To conserve the template mesh’s topological properties, we train our model over a set of diffeomorphic transformations. This framework can generate surfaces with several hundred thousand vertices in seconds requiring only a small GPU memory footprint. We evaluate its performance for the challenging task of brain cortical surface reconstruction from MRI.
A Comparison of Saliency Methods for Deep Learning Explainability
Salamata Konate, Léo Lebrat, Rodrigo Santa Cruz, Elliot Smith, Andrew Bradley, Clinton Fookes, and Olivier Salvado2021 Digital Image Computing: Techniques and Applications (DICTA).

Saliency methods are widely used to visually explain black-box deep learning model outputs to humans. In this paper, we compare the Gradient method, Grad-CAM, Extremal perturbation, and DEEPCOVER, and highlight the complexity in determining which method provides the best explanation of a CNN’s decision.
Detail Matters: High-Frequency Content for Realistic Synthetic MRI Generation
Filip Rusak, Rodrigo Santa Cruz, Elliot Smith, Jurgen Fripp, Clinton Fookes, Pierrick Bourgeat, and Andrew BradleyIn the International Workshop on Simulation and Synthesis in Medical Imaging at MICCAI, 2021.
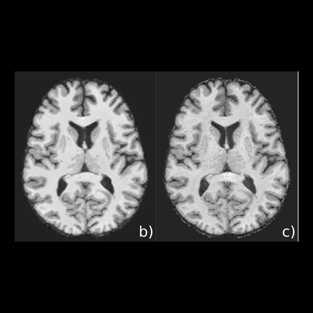
In this work, we investigate whether, and to what extent, the high-frequency (HF) detail in synthetic brain MR images (MRIs) impacts the performance of DL-based segmentation methods. To assess the impact of HF detail, we generate two synthetic datasets, with and without HF detail and train corresponding segmentation models to evaluate the impact on their performance.
MongeNet: Efficient Sampler For Geometric Deep Learning
Léo Lebrat*, Rodrigo Santa Cruz*, Clinton Fookes, and Olivier SalvadoIn IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021. * equal contribution.

This paper proposes a novel algorithm to sample point clouds from triangular meshes. We formulate this problem as an optimal transport problem between simplexes and discrete Dirac measures, and develop an algorithm to compute the optimal solution. Due to the computational challenge of this algorithm, we train a neural network, named MongeNet, to predict its solution efficiently. MongeNet can be adopted as a mesh sampler during training or testing of 3D deep learning models providing a better representation of the underlying surface with a very small computational overhead.
Going Deeper With Brain Morphometry Using Neural Networks
Rodrigo Santa Cruz, Léo Lebrat, Pierrick Bourgeat, Vincent Doré, Jason Dowling, Jurgen Fripp, Clinton Fookes, and Olivier SalvadoIn IEEE International Symposium on Biomedical Imaging (ISBI), 2021
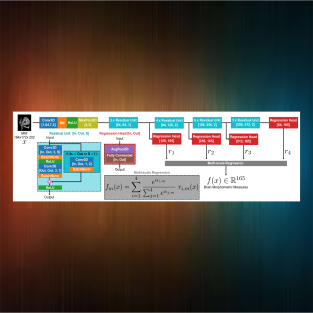
In this paper, we propose a more accurate and efficient neural network model for brain morphometry named HerstonNet. More specifically, we develop a 3D ResNet-based neural network to learn rich features directly from MRI, design a multi-scale regression scheme by predicting morphometric measures at feature maps of different resolutions, and leverage a robust optimization method to avoid poor quality minima and reduce the prediction variance. As a result, HerstonNet improves the existing approach by 24.30% in terms of intraclass correlation coefficient (agreement measure) to FreeSurfer silver-standards while maintaining a competitive run-time.
SMOCAM: SMOoth Conditional Attention Mask for 3D-Regression Models
Salamata Konate, Léo Lebrat, Rodrigo Santa Cruz, Pierrick Bourgeat, Vincent Doré, Jurgen Fripp, Andrew Bradley, Clinton Fookes, and Olivier SalvadoIn IEEE International Symposium on Biomedical Imaging (ISBI), 2021
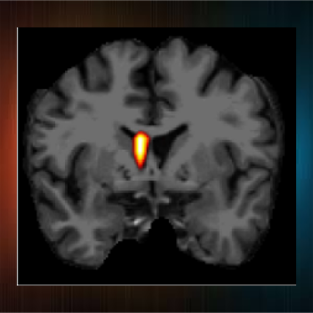
Despite the pervasive growth of deep neural networks in medical image analysis, methods to monitor and assess network outputs, such as segmentation or regression, remain limited. In this paper, we introduce SMOCAM (SMOoth Conditional Attention Mask), an optimization method that reveals the specific regions of the input image taken into account by the prediction of a trained neural network. We developed SMOCAM explicitly to perform saliency analysis for complex regression tasks in 3D medical imagery like brain morphometry from MRI.
DeepCSR: A 3D Deep Learning Approach for Cortical Surface Reconstruction
Rodrigo Santa Cruz, Leo Lebrat, Pierrick Bourgeat, Clinton Fookes, Jurgen Fripp, and Olivier SalvadoIn IEEE Winter Conference on Applications of Computer Vision (WACV), 2021.
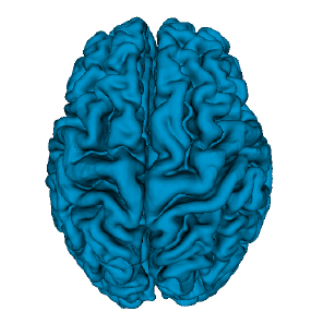
In this paper, we propose a 3D deep learning framework for cortical surface reconstruction from MR images named DeepCSR. More specifically, we first reformulate this problem as the prediction of an implicit surface representation for points in a continuous coordinate system. Then, the cortical surfaces are extracted using this implicit surface representation, a lightweight topological correction method, and an isosurface mesh extraction technique.
3D Brain MRI GAN-Based Synthesis Conditioned on Partial Volume Maps
Filip Rusak, Rodrigo Santa Cruz, Pierrick Bourgeat, Clinton Fookes, Jurgen Fripp, Andrew Bradley, and Olivier SalvadoIn the International Workshop on Simulation and Synthesis in Medical Imaging at MICCAI, 2020.
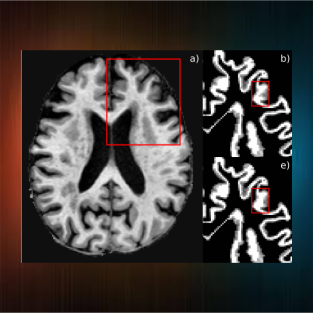
In this paper, we propose a GAN-Based framework for synthesising 3D brain T1-weighted (T1-w) MRI images from Partial Volume (PV) maps for the purpose of generating synthetic MRI volumes with more accurate tissue borders.
Inferring Temporal Compositions of Actions Using Probabilistic Automata
Rodrigo Santa Cruz, Anoop Cherian, Basura Fernando, Dylan Campbell, and Stephen GouldIn Workshop on Compositionality in Computer Vision at CVPR, 2020.
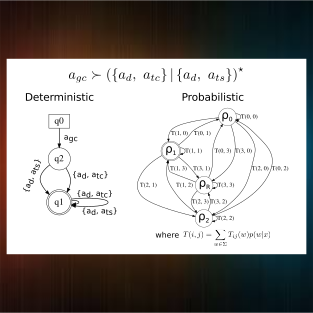
In this paper, we address the problem of recognizing complex compositional activities in videos. To this end, we describe activities unambiguously as regular expressions of simple primitive actions and derive framework based on Probabilistic Automata to recognize instances of these regular expressions in videos.
Visual Recognition From Structured Supervision
Rodrigo Santa CruzPh.D. Thesis, Australian National University (ANU), December 2019.

This thesis describes methods that reduce the need for human supervision when training deep learning models by leveraging the structure in the visual world targeting visual recognition in difficult scenarios where annotated data is scarce and the visual concepts are innumerable or ambiguous.
Visual Permutation Learning
Rodrigo Santa Cruz, Basura Fernando, Anoop Cherian, and Stephen GouldIn IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2018.
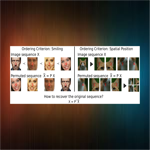
We present a principled approach to uncover the structure of visual data by solving a deep learning task coined visual permutation learning. To this end, we resort to a continuous approximation using doubly-stochastic matrices, formulate a novel bi-level optimization problem, and propose a computationally cheap scheme based on Sinkhorn iterations. The utility of these models are demonstrated on relative attributes learning, supervised learning-to-rank, and self-supervised representation learning.
Neural Algebra of Classifiers
Rodrigo Santa Cruz, Basura Fernando, Anoop Cherian, and Stephen GouldIn IEEE Winter Conference on Applications of Computer Vision (WACV), 2018.
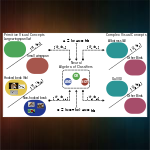
We build on the compositionality principle and develop an “algebra” to compose classifiers for complex visual concepts. To this end, we learn neural network modules to perform boolean algebra operations on simple visual classifiers. Since these modules form a complete functional set, a classifier for any complex visual concept defined as a boolean expression of primitives can be obtained by recursively applying the learned modules, even if we do not have a single training sample.
DeepPermNet: Visual Permutation Learning
Rodrigo Santa Cruz, Basura Fernando, Anoop Cherian, and Stephen GouldIn IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
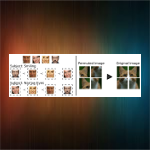
We present a principled approach to uncover the structure of visual data by solving a novel deep learning task coined visual permutation learning. Moreover, we propose DeepPermNet, an end-to-end CNN model for this task. The utility of our proposed approach is demonstrated on two challenging computer vision problems, namely, relative attributes learning and self-supervised representation learning.
On Differentiating Parameterized Argmin and Argmax Problems with Application to Bi-level Optimization
Stephen Gould, Basura Fernando, Anoop Cherian, Peter Anderson, Rodrigo Santa Cruz, and Edison GuoTechnical Report, available online on arXiv, 2016.
In this technical report we collect some results on differentiating argmin and argmax optimization problems with and without constraints and provide some insightful motivating applications. Such results are very useful for developing end-to-end gradient based learning methods.
Human detection in digital videos using motion features extractors
Rodrigo F. S. C. Oliveira and Carmelo J. A. Bastos-FilhoIn IEEE Latin American Conference on Computational Intelligence (LA-CCI), 2016.

We combine motion features to the Aggregated Channel Features (ACF) pedestrian detector. We demonstrate that motion features can provide more accurate results and reduce false alarms.
Bayesian Model Averaging Naive Bayes: Averaging over an Exponential Number of Feature Models in Linear Time
Ga Wu, Scott Sanner, and Rodrigo F. S. C. OliveiraIn Proceedings of the 29th Conference on Artificial Intelligence (AAAI), 2015.
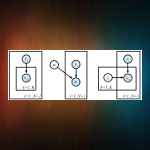
We demonstrate that it is possible to exactly evaluate Bayesian model averaging (BMA) over the exponentially-sized powerset of Naive Bayes (NB) feature models in linear-time in the number of features; this yields an algorithm about as expensive to train as a single NB model with all features, but yet provably converges to the globally optimal feature subset in the asymptotic limit of data.
Regenerator Placement and Link Capacity Optimization in Translucent Optical Networks Using a Multi-objective Evolutionary Algorithm
Renan V. Carvalho, Rodrigo F. Oliveira, Carmelo J. Bastos Filho, Daniel A. Chaves, and Joaquim F. Martins Filho.In Proceedings of Optical Fiber Conference (OFC/NFOEC), 2012.
We present an Evolutionary algorithm to tackle simultaneously the regenerator placement and link capacity optimization problems in translucent optical networks. Our proposed method can assist a network designer to manage resources balancing cost and performance.